
Das Forschungsprojekt »Silke – Sichere Lebensmittelkette durch die Anwendung der Blockchain-Technologie« beschäftigt sich mit der Entwicklung einer Blockchain-Lösung, die eine vollständige Transparenz für Lieferketten über alle Warengruppen hinweg garantieren kann.
In der Lebensmittelindustrie werden selten integrierte Systeme zur Informationsweitergabe über die ganze Lieferkette hinweg verwendet. Dadurch sind Unternehmen kaum in der Lage, allen Anforderungen hinsichtlich der Rückverfolgbarkeit, die über die gesetzlichen hinausgehen, ausreichend nachzukommen. In der Vergangenheit hat dies dazu geführt, dass die Identifizierung der Ursachen von Verunreinigungen viel Zeit in Anspruch nahm und somit eine Gefährdung lange bestehen blieb. Die Identifikation der Ursache, sowie die Erfassung und Isolierung der verunreinigten Lebensmittel im Handel und dem weltweitem Distributionsgebiet, sind sehr aufwendig.
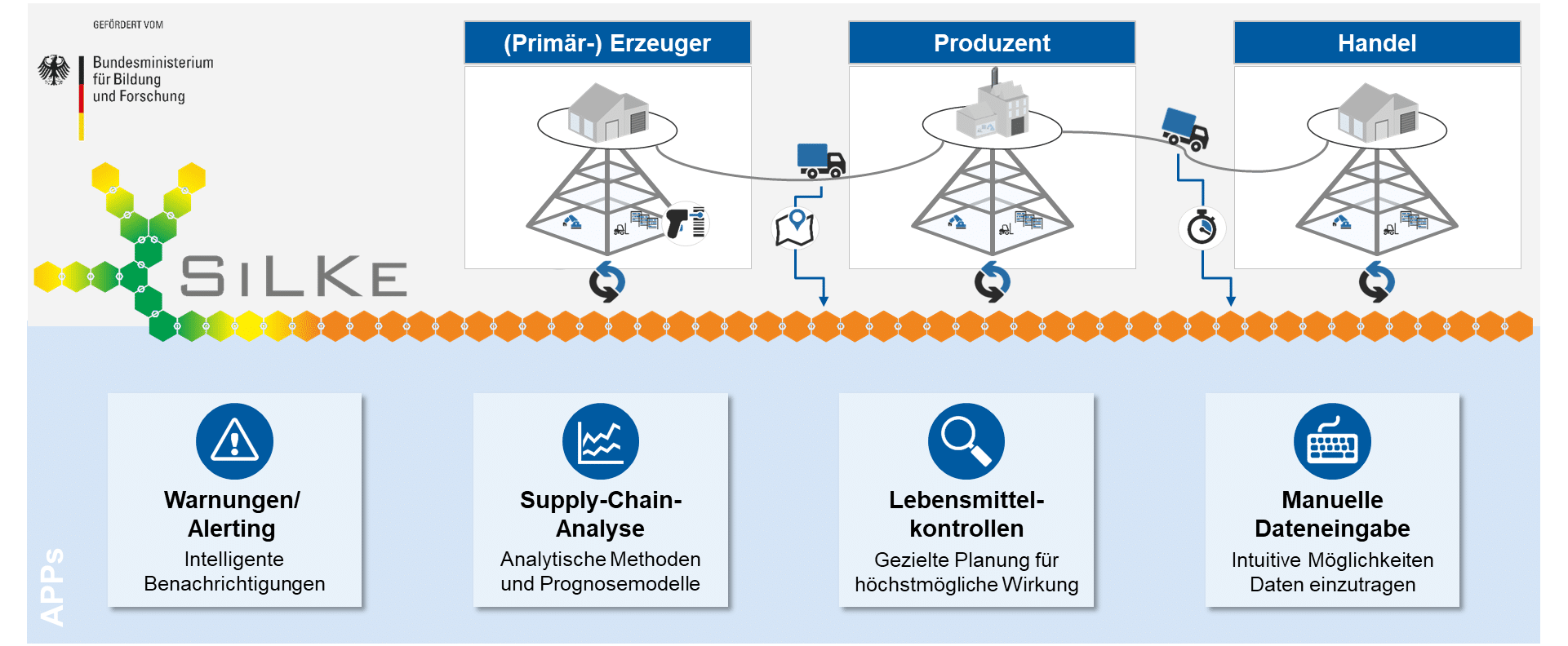
Zielbild des Projektes Silke.
Das Forschungsprojekt »Silke – Sichere Lebensmittelkette durch die Anwendung der Blockchain-Technologie« stellt ein anbieterneutrales und bundesweites Projekt dar und wird vom Bundesministerium für Bildung und Forschung gefördert. Beteiligte Partner sind das FIR e. V. an der RWTH Aachen, das Fraunhofer-Institut für Angewandte Informationstechnik, die fTrace GmbH, das FZI Forschungszentrum Informatik, die Hochschule Niederrhein, die PSI Logistics GmbH, die Qinum GmbH sowie verschiedene assoziierte Partner aus der Praxis.
Im Rahmen des Projekts untersucht das Konsortium von Institutionen aus Wissenschaft und Industrie, inwieweit durch Anwendung der Blockchain-Technologie die Sicherheit und Transparenz in Lebensmittellieferketten erhöht werden kann. Es gilt eine klare Rückverfolgbarkeit zu ermöglichen und gleichzeitig die Fälschungssicherheit der Informationen sicherzustellen.
Dezentrales, digitales Netzwerk
Die Anwendung der Blockchain-Technologie ermöglicht den Aufbau eines dezentralen, digitalen und fälschungssicheren Netzwerks. In dieses Netzwerk können alle beteiligten Akteure Daten schreiben, um Transaktionen chronologisch und unveränderbar abzuspeichern. Außerdem können diese Daten entsprechend der Zugriffsberechtigungen gelesen werden.
Vorgehensweise im Projekt ist anfangs, die anwenderseitigen Anforderungen der Industrie, der Behörden und des Konsumenten zu erheben (Lastenheft). Hier stehen die Reichweite der Freigabe und die erwünschte Vertraulichkeit von unternehmensbezogenen Daten im Vordergrund. Darauf aufbauend wird ein Modell einer blockchainbasierten Gesamtarchitektur entworfen (Pflichtenheft). Anhand dessen wird ein Blockchain-Netzwerk für den konkreten Anwendungsfall implementiert. Entwickelte Silke-Applikationen sollen dem Nutzer die Visualisierung und Analyse ihrer Daten ermöglichen. Validiert wird die Blockchain mit Hilfe von zwei konkreten Anwendungsfällen. Der abschließend erstellte Demonstrator veranschaulicht dem Nutzer die auf Basis der Blockchain-Technologie erarbeiteten Lösungen.
Referenzmodell
Würde ein einzelnes Unternehmen eine Rückverfolgungslösung entwickeln, wäre klar, dass es ein Lastenheft passend für den eigenen Betrieb verfasst. Da in dem Forschungsprojekt jedoch eine allgemeine Lösung entwickelt werden soll, war eine möglichst generische Abbildung beliebiger Logistikprozesse notwendig. Hierfür wurde ein logistisches Referenzmodell entwickelt, das es ermöglichen soll, jeden beliebigen betriebsspezifischen Einzelfall hinreichend genau abzubilden. Dieses Referenzmodell stellt damit die Grundlage für die Konzeptionierung und letztendliche Umsetzung der technischen Lösung dar. Zur Beschreibung wurden etablierte Referenzmodelle (zum Beispiel Porter‘s Value Chain oder das SCOR-Modell) herangezogen und entsprechend der Problemstellung angepasst. Die grundlegende Überlegung ist die Folgende: Jeder beliebige Logistikprozess besteht aus einer Aneinanderreihung einzelner Schritte, alle möglichen Schritte der Praxis lassen sich jedoch durch eine überschaubare Menge von allgemein gehaltenen Schritten beschreiben. So ist zum Beispiel das Lagern von frischem Obst von dem Lagern frisch gefangenen Fisches in der Praxis grundverschieden. Beide lassen sich jedoch als das Lagern unter spezifischen Bedingungen, in festgelegten Behältnissen und für einen definierten Zeitraum beschreiben. Sieht die Softwarelösung nun einen solchen allgemeinen Schritt vor, muss im Anwendungsfall lediglich die betriebsbezogene Spezifizierung vorgenommen werden. So wurden knapp 40 allgemeine Schritte beschrieben, die es ermöglichen, so gut wie jeden realen Logistikprozess vollständig abzubilden. Im Umkehrschluss ermöglicht das, eine für diese allgemeinen Schritte ausgelegte technische Rückverfolgungslösung im konkreten Anwendungsfall der Praxis unter minimiertem Aufwand im eigenen Unternehmen aufzunehmen. Hiermit wird jedem Unternehmen das Nutzen der Forschungsergebnisse im eigenen Betrieb erleichtert und es wird sichergestellt, dass Entwicklungsaufwand und Investitionsrisiko möglichst gering sind.
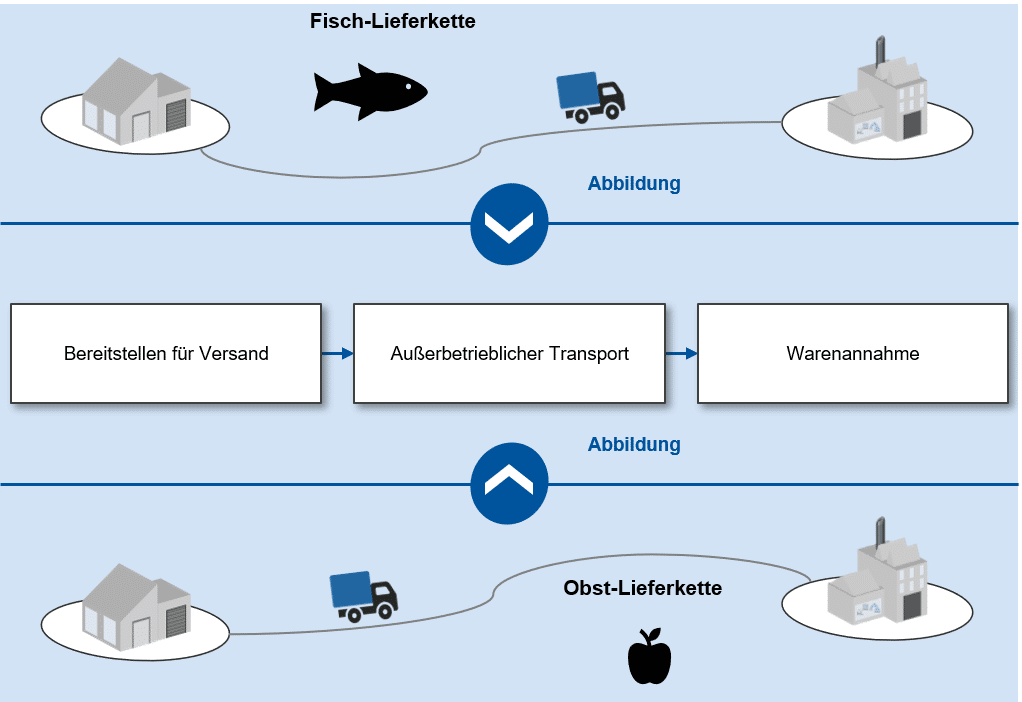
Exemplarische Darstellung des Referenzmodells.
Datenbedarfe
Um das Referenzmodell mit betriebsbezogenen Spezifikationen zu erweitern, wurden relevante gesetzliche, logistische und technische Informationen gesammelt, mit deren Hilfe eine geeignete Referenz-Architektur aufgebaut werden kann. Die Erhebung der Datenbedarfe wurde mit Hilfe von Experteninterviews und Erfahrungen aus anderen Projekten der Konsortialpartner validiert. Die daraus generierten Informationen wurden in einer Matrix vereinigt. Mit Hilfe dieser lassen sich die Datenbedarfe unter anderem nach den möglichen Eingabe- und Ausgabe-Akteuren, der Notwendigkeit der Rückverfolgbarkeit, den gesetzlichen Vorgaben und den Schritten aus dem Referenzmodell kategorisieren. So kann festgelegt werden, welcher Datenbedarf an welcher Position der gesamten Wertschöpfungskette relevant ist und in die Referenz-Architektur implementiert werden muss.
Zur Analyse der gesetzlichen Datenbedarfe wurden alle lebensmittelrelevanten Gesetze, Normen, Richtlinien und Standards auf Aspekte der Rückverfolgbarkeit untersucht. Die filtrierten rechtlichen Textpassagen wurden in eindeutig definierte Datenbedarfe umformuliert und in allgemeingültig und warengruppenspezifisch unterschieden, damit eine universell einsetzbare Lösung für alle Lebensmittelwarengruppen geschaffen werden kann. Während der Analyse wurde entschieden zusätzlich Datenbedarfe abzubilden, die für eine Traceability nicht notwendig sind, jedoch einen Mehrwert für das Unternehmen und seine Stakeholder schaffen.
Die logistischen Datenbedarfe wurden detailliert ermittelt, indem die verschiedenen Stakeholder der Lebensmittellogistik identifiziert und deren spezifischen Anforderungen erhoben wurden.
Die technischen Datenbedarfe, also die Anforderungen aus Sicht der primär- und weiterverarbeitenden Produktion, sind von den Forschungs- und Industriepartnern zusammengetragen worden.
Insgesamt wurden rund 100 Datenbedarfe ermittelt, die nun als Input für das weitere Vorgehen im Projekt Silke genutzt werden.◂
Unsere Autoren
Autoren und Ansprechpartner des Projekts sind:Martina Thume, Hochschule Niederrhein
Martina.Thume@hs-niederrhein.de
02161/1865322David Holtkemper, FIR e. V. an der RWTH Aachen
David.Holtkemper@fir.rwth-aachen.de
0241/47705432Weitere Autoren:
Bastian Bürklin, FIR e. V. an der RWTH Aachen
Sven Dütting, Hochschule Niederrhein, Mönchengladba ch
Elena Westhofen, Hochschule Niederrhein, MönchengladbachWeitere Informationen unter silke.fir.de.





